There's an additional way to run aggregation over a table. If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed. Knowing how to use a SQLGROUP BY statement whenever you have aggregate functions is essential.
In most cases, when you need an aggregate function, you must add aGROUP BY clause in your query too. The first must contain a distinct first name of the employee and the second – the number of times this name is encountered in our database. Once the rows are divided into groups, the aggregate functions are applied in order to return just one value per group. It is better to identify each summary row by including the GROUP BY clause in the query resulst. All columns other than those listed in the GROUP BY clause must have an aggregate function applied to them. The most important preconditions for using indexes for GROUP BY are that all GROUP BY columns reference attributes from the same index, and that the index stores its keys in order .

Aggregates applied to all the qualifying rows in a table are called scalar aggregates. An aggregate function in the select list with no group by clause applies to the whole table; it is one example of a scalar aggregate. All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions . In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both.
It is not permissible to include column names in a SELECT clause that are not referenced in the GROUP BY clause. The only column names that can be displayed, along with aggregate functions, must be listed in the GROUP BY clause. Since ENAME is not included in the GROUP BYclause, an error message results. The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns. This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses.
Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT. The above query includes the GROUP BY DeptId clause, so you can include only DeptId in the SELECT clause. You need to use aggregate functions to include other columns in the SELECT clause, so COUNT is included because we want to count the number of employees in the same DeptId. You must use the aggregate functions such as COUNT(), MAX(), MIN(), SUM(), AVG(), etc., in the SELECT query. The result of the GROUP BY clause returns a single row for each value of the GROUP BY column. The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM().

In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category. The HAVING clause filters group rows created by the GROUP BY clause. The HAVING clause is applied to each group of the grouped table, much as a WHERE clause is applied to a select list.
If there is no GROUP BY clause, the HAVING clause is applied to the entire result as a single group. The SELECT clause cannot refer directly to any column that does not have a GROUP BY clause. If the WITH TOTALS modifier is specified, another row will be calculated. This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values).

ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions. Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on. Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set. The GROUP BY clause is a SQL command that is used to group rows that have the same values.

Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. The aggregate functions do not include rows that have null values in the columns involved in the calculations; that is, nulls are not handled as if they were zero. GROUP BY is used in conjunction with aggregate functions to filter the results by a value. The GROUP BY command can be very useful for viewing a select set of results.

It is commonly used, which deems it essential to utilize the proper syntax when running the statement. Use theSQL GROUP BYClause is to consolidate like values into a single row. The group by returns a single row from one or more within the query having the same column values. Its main purpose is this work alongside functions, such as SUM or COUNT, and provide a means to summarize values. The GROUP BY clause is part of the SQL SELECT statement. Optionally it is used in conjunction with aggregate functions to produce the resulting group of rows from the database.

While the first query is not needed, I've used it to show what it will return. I did that because this is what the second query counts. This statement will return an error because you cannot use aggregate functions in a WHERE clause.
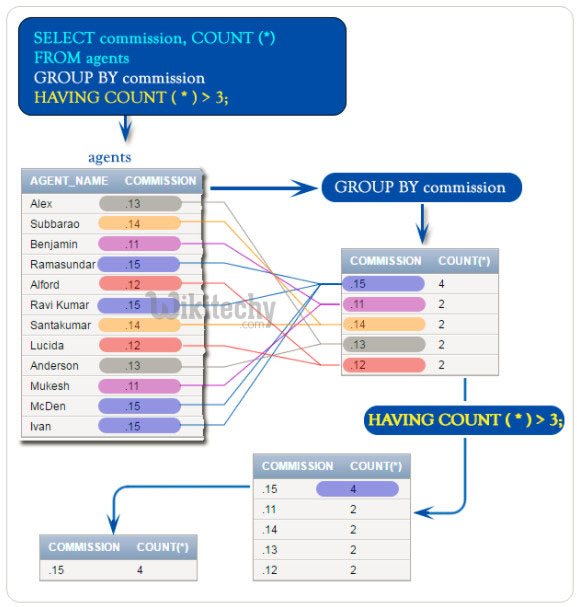
WHERE is used with GROUP BY when you want to filter rows before grouping them. Here, you can add the aggregate functions before the column names, and also a HAVING clause at the end of the statement to mention a condition. In this query, all rows in the EMPLOYEE table that have the same department codes are grouped together.
The aggregate function AVG is calculated for the salary column in each group. The department code and the average departmental salary are displayed for each department. The HAVING clause in a SELECT specifies a condition to apply within a group or aggregate. In other words, HAVING filters rows after the aggregation of the GROUP BY clause has been applied. Since HAVING is evaluated after GROUP BY, it can only reference expressions constructed from grouping keys, aggregate expressions, and constants. (These are the same rules that apply to expressions in the SELECT clause of a GROUP BY query.) A HAVING clause must come after any GROUP BY clause and before any ORDER BY clause.

Results from a HAVING clause represent groupings or aggregations of original rows, whereas results from a WHERE clause are individual original rows. Adding a HAVING clause after your GROUP BY clause requires that you include any special conditions in both clauses. If the SELECT statement contains an expression, then it follows suit that the GROUP BY and HAVING clauses must contain matching expressions. It is similar in nature to the "GROUP BY with an EXCEPTION" sample from above. In the next sample code block, we are now referencing the "Sales.SalesOrderHeader" table to return the total from the "TotalDue" column, but only for a particular year.
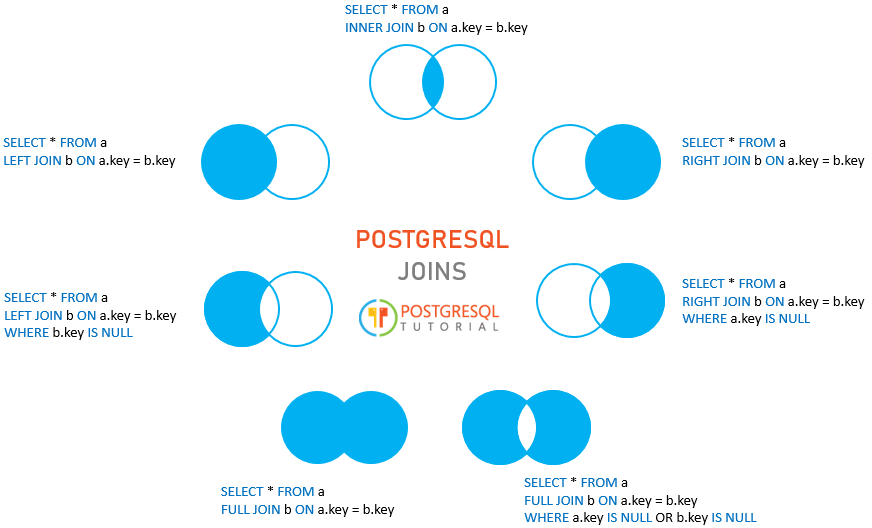
Which SQL query must have must have a group by clause The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. In conclusion, we didn't say that the SQLGROUP BY clause is one of the most powerful tools out there for no reason. It is preferred over the SELECT DISTINCT statement because it can be combined with aggregate functions.

You can also use it with SQLORDER BY. However, you must make sure that you keep the right order when writing it. But this technique is constantly being applied in queries, as it clarifies the analysis undertaken. If you are interested in learning about what else you can combine with the GROUP BY statement, you can learn all about the HAVING clause. HAVING and WHERE are often confused by beginners, but they serve different purposes. WHERE is taken into account at an earlier stage of a query execution, filtering the rows read from the tables.

If a query contains GROUP BY, rows from the tables are grouped and aggregated. After the aggregating operation, HAVING is applied, filtering out the rows that don't match the specified conditions. Therefore, WHERE applies to data read from tables, and HAVING should only apply to aggregated data, which isn't known in the initial stage of a query.

HAVING Clause is used as a conditional statement with GROUP BY Clause in SQL. WHERE Clause cannot be combined with aggregate results so Having clause is used which returns rows where aggregate function results matched with given conditions only. This statement is used to group records having the same values. The GROUP BY statement is often used with the aggregate functions to group the results by one or more columns. The only aggregate functions used in the select list are MIN() and MAX(), and all of them refer to the same column.
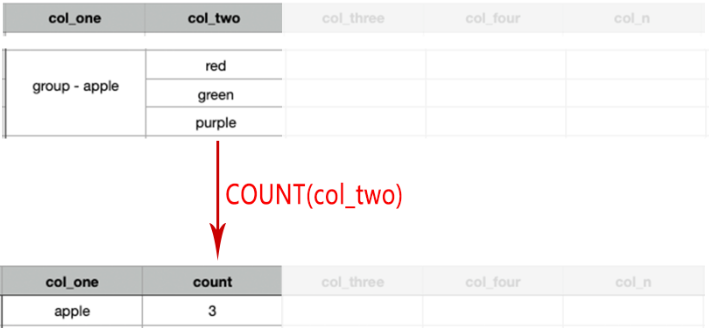
The column must be in the index and must immediately follow the columns in the GROUP BY. In some cases, MySQL is able to do much better than that and avoid creation of temporary tables by using index access. However, you can use the GROUP BY clause with CUBE, GROUPING SETS, and ROLLUP to return summary values for each group. The SUM() function returns the total value of all non-null values in a specified column. Since this is a mathematical process, it cannot be used on string values such as the CHAR, VARCHAR, and NVARCHAR data types. When used with a GROUP BY clause, the SUM() function will return the total for each category in the specified table.

In the first SELECT statement, we will not do a GROUP BY, but instead, we will simply use the ORDER BY clause to make our results more readable sorted as either ASC or DESC. IIt is important to note that using a GROUP BY clause is ineffective if there are no duplicates in the column you are grouping by. A better example would be to group by the "Title" column of that table.

The SELECT clause below will return the six unique title types as well as a count of how many times each one is found in the table within the "Title" column. The HAVING keyword works exactly like the WHERE keyword, but uses aggregate functions instead of database fields to filter. Write a query that will return both the maximum and minimum average salary grouped by department from the employees table. The GROUP BY statement is often used with aggregate functions to group the result-set by one or more columns. Remember, if you are using an aggregate function in your select query then you must also have a GROUP BY clause.

You cannot refer to a nonaggregated column in SELECT that is not also named in the GROUP BY clause. For the query to run successfully you must either remove the group function or column expression from SELECT or you must add a GROUP BY clause that includes the column expression. We'll call columns/expressions that are in SELECT without being in an aggregate function, nor in GROUP BY,barecolumns. In other words, if our results include a column that we're not grouping by and we're also not performing any kind of aggregation or calculation on it, that's a bare column. Aggregate functions are functions that take a set of rows as input and return a single value. In SQL we have five aggregate functions which are also called multirow functions as follows.

In addition to producing all the rows of a GROUP BY ROLLUP, GROUP BY CUBE adds all the "cross-tabulations" rows. Sub-total rows are rows that further aggregate whose values are derived by computing the same aggregate functions that were used to produce the grouped rows. While all aggregate functions could be used without the GROUP BY clause, the whole point is to use the GROUP BY clause. That clause serves as the place where you'll define the condition on how to create a group.
When the group is created, you'll calculate aggregated values. A. It throws an error because the aggregate functions used in HAVING clause must be in SELECT list. Use the GROUP BY clause with aggregate functions in a SELECT statement to collect data across multiple records. In this lesson you learned to use the SQL GROUP BY and aggregate functions to increase the power expressivity of the SQL SELECT statement. You know about the collapse issue, and understand you cannot reference individual records once the GROUP BY clause is used.

We can use HAVING clause to place conditions to decide which group will be the part of final result-set. Also we can not use the aggregate functions like SUM(), COUNT() etc. with WHERE clause. So we have to use HAVING clause if we want to use any of these functions in the conditions. Like most things in SQL/T-SQL, you can always pull your data from multiple tables. Performing this task while including a GROUP BY clause is no different than any other SELECT statement with a GROUP BY clause.

The fact that you're pulling the data from two or more tables has no bearing on how this works. In the sample below, we will be working in the AdventureWorks2014 once again as we join the "Person.Address" table with the "Person.BusinessEntityAddress" table. I have also restricted the sample code to return only the top 10 results for clarity sake in the result set. Another extension, or sub-clause, of the GROUP BY clause is the CUBE. The CUBE generates multiple grouping sets on your specified columns and aggregates them.

In short, it creates unique groups for all possible combinations of the columns you specify. For example, if you use GROUP BY CUBE on of your table, SQL returns groups for all unique values , , and . This is your most expensive department in terms of salary. In the previous episode, we have seen the keyword WHERE, allowing to filter the results according to some criteria. SQL offers a mechanism to filter the results based on aggregate functions, through the HAVING keyword. WITH CUBE modifier is used to calculate subtotals for every combination of the key expressions in the GROUP BY list.
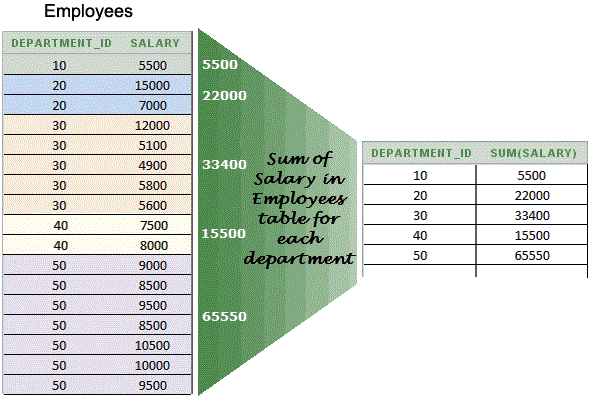
WITH ROLLUP modifier is used to calculate subtotals for the key expressions, based on their order in the GROUP BY list. HAVING clause's key advantage is its ability to filter GROUPS using aggregate functions. This is something you cannot do withing a SELECT statement. The GROUP BY clause divides the rows returned from the SELECTstatement into groups. For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups. JOINS are SQL statements used to combine rows from two or more tables, based on a related column between those tables.

We can use the SQL GROUP BY statement to group the result set based on a column/ columns. In this query, the rows are grouped by department and, within each department, employees with the same benefits are grouped so that totals can be computed. Notice that the columns DEPT and BENEFITS can appear in the SELECT statement since both columns appear in the GROUP BY clause. In this example, the aggregate function AVG is used in a SELECTstatement that has a WHERE clause. Texis selects the rows that represent Marketing Department employees and then applies the aggregate function to these rows.
The HAVING clause was added to SQL because theWHERE keyword cannot be used with aggregate functions. Note – There is a restriction regarding the use of columns in the GROUP BY clause. Each column appearing in the SELECT list of the query must also appear in the GROUP BY clause.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.